
27. März 2025

Willi Linke
Co-founder
Modern marketing teams have one primary goal - maximizing the return of every marketing dollar spent. To achieve this, growth teams have to analyze the impact of their budgets, so that their channels can be optimized to increase the relevant KPI’s.
The traditional way to measure impact is to run A/B tests - analyzing how different versions of the product, the landingpage or messaging affect their marketing efficiency.
However, not everything can be A/B tested—whether because of feasibility, ethical concerns, or practical constraints.
Take paid ads, for example. Ideally, you’d want to know which campaigns will drive valuable traffic before committing extensive budgets. But how do you identify high-potential traffic beforehand?
This is where treatment effects come into play. In this blog post, we’ll explore how they work, and how you can find valuable customer segments without sacrificing your budget beforehand.
Let’s go.
The Broad Dilemma
10 years ago, marketers used fine-grained targeting strategies and micro-segments to test and improve their reach. However, with the rise of automated ad placement technologies like PMax and Advantage+ Shopping, the ability to micro-control targeting strategies has diminished.
Today, adTech giants rely on machine-learning-based audience selection, instead of micro-cohorts or fine-grained audience signals.
If you look from a holistic perspective, audience coverage is mostly determined by external platform algorithms, which marketers delegate their targeting to —letting the algorithms identify and reach potential customer segments (those are the broad targeting option we all love).

Interestingly, this approach often leads to fading new customer ratios, when Google or Meta can’t find new valuable segments but don’t want to stop spending your budgets.
At this point a new approach to identifying customer segments is mandatory for any growth team.
Causal Analytics to the Rescue!
While reaching new customer segments within ad networks has become increasingly challenging, the good news is that it is still possible and it is conducted through what is known as an observational study.
An observational study is a statistical method that analyzes the causal effect of an action while accounting for pre-existing conditions that might influence the outcome.
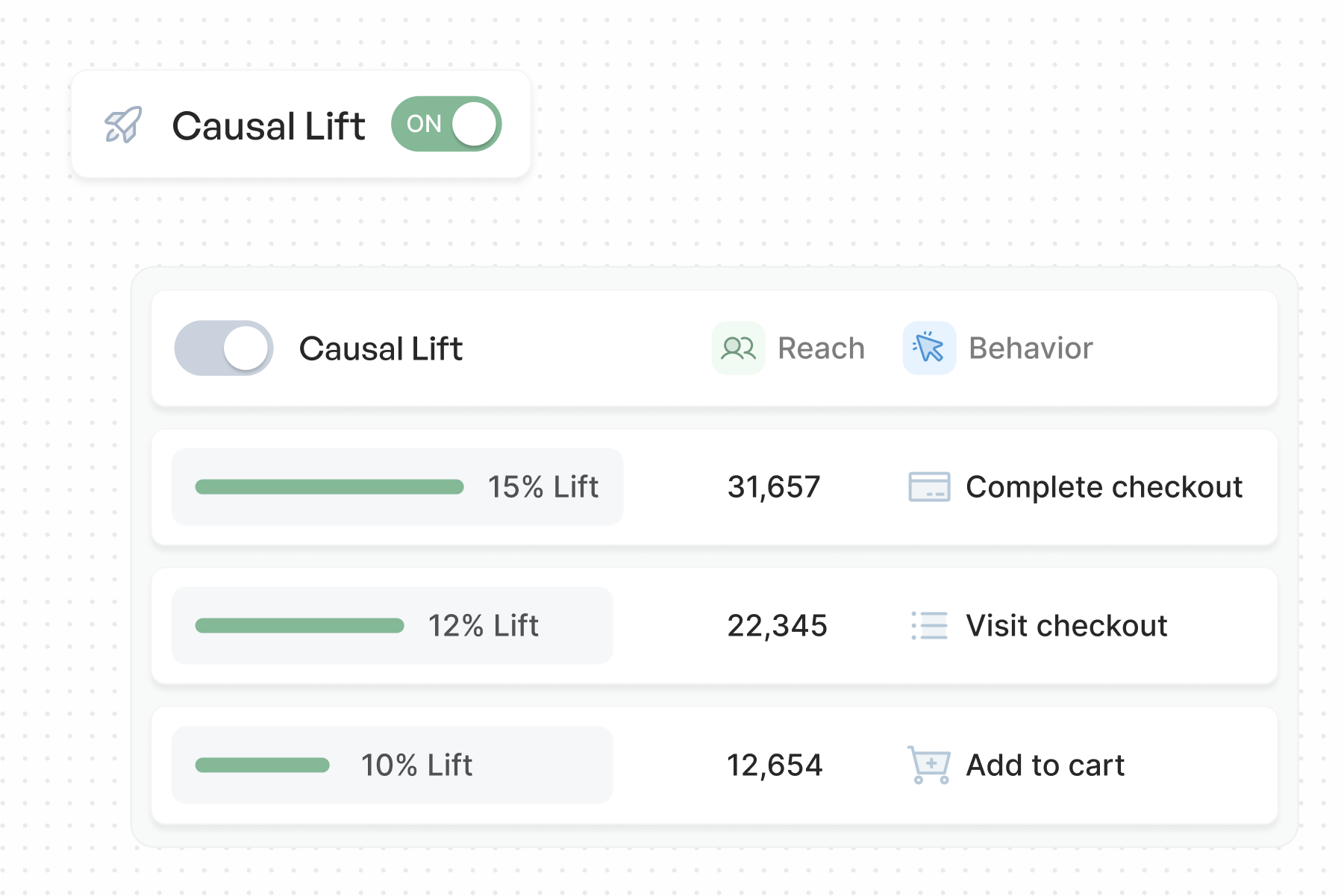
For example, suppose you want to determine whether a user is more likely to complete a checkout after seeing one of your ads. By predicting the true causal effect of the ad exposure on the users checkout probability, we can identify highly relevant users where additional marketing budget might generate significantly more new business for your company.
In data science, this effect is called Average Treatment Effect (ATE).
Average Treatment Effects
A treatment effect measures the average causal impact of a binary action (e.g., showing an ad vs. not showing an ad) on an outcome variable (e.g., revenue or conversions). The concept originates from medical research, where treatment effects were used to assess the impact of experimental drugs.
In marketing, treatment effects help forecast, for example, the impact of an Instagram ad impression on a user’s expected revenue.
To calculate treatment effects, we define the following:
Y₁ᵢ: Potential revenue of user i if they see the Instagram ad (the treated outcome).
Y₀ᵢ: Potential revenue of user i if they do not see the ad (the control outcome).
Dᵢ: A binary indicator (1 if the user sees the ad, 0 otherwise).
The observed revenue for user i is:
yᵢ = Y₀ᵢ + Dᵢ(Y₁ᵢ − Y₀ᵢ)
This means we observe Y₁ᵢ for treated users and Y₀ᵢ for untreated users, but never both for the same individual — a fundamental challenge in causal inference.
Using E[·], the expectation (or average) operator, two commonly studied treatment effects are:
Average Treatment Effect (ATE):
E[Y₁ − Y₀] — the expected additional revenue from showing the ad, averaged across all users.
Conditional Average Treatment Effect (CATE):
E[Y₁ − Y₀ | X = x] — the expected treatment effect for a specific subgroup of users with characteristics X = x.
Sometimes also used more narrowly to refer to E[Y₁ − Y₀ | D = 1], i.e., the expected effect among treated users.
Since we cannot observe both Y₁ᵢ and Y₀ᵢ for the same user, we estimate these effects using historical data and statistical models, such as propensity score matching, regression adjustment, or machine learning-based uplift modeling. This enables us to predict the incremental lift in revenue due to ad exposure and to identify users who are more likely to convert because they saw the ad - not just those who would have converted anyway.
Getting Treatment Effects to Work (The Innkeepr Approach)
Now that we understand how to predict ad impact, we can leverage treatment effects to:
Identify high-relevant user segments with early intent.
Introduce a system of continuous learning to improve targeting precision.

This approach enables us to continuously discover and model new audience segments for every campaign in every marketing channel—moving beyond broad targeting strategies for additional scale.
Putting Audience Optimization to Practice
Now that you know how to estimate the causal effect of your marketing efforts, what can you do with this information? At Innkeepr, we’ve seen our customers use causal analytics in three powerful ways:
1. Increasing New Customer Ratios with Lookalike Seeds
Instead of relying solely on historical customer data, advertisers can create lookalike audiences using users with high predicted ad impact. This approach has been shown to increase new customer acquisition rates by 10-35%.
2. Suppressing Ad Spend on Low-Impact Segments
Just as important as identifying high-potential audiences is excluding low-value segments. By using intelligent exclusion lists based on low expected treatment effects, marketers can protect their budgets from wasted spend.
3. Retargeting Users for the “Next Best Action”
Knowing which users are about to churn is invaluable for crafting preemptive counter-strategies. Whether it’s offering a 10% discount or free shipping for abandoned carts, understanding the expected economic value of a churning user allows for more strategic interventions.
We are excited about the future of causal analytics at Innkeepr. If you’re interested in learning more about how causal analytics can change the way you approach growth, sign up now!